5. Running the SRW App
This chapter explains how to set up and run the “out-of-the-box” case for the SRW Application. However, the steps are relevant to any SRW App experiment and can be modified to suit user goals. This chapter assumes that users have already built the SRW App by following the steps in Chapter 4. These steps are also applicable to containerized versions of the SRW App and assume that the user has completed all of Section 3.1.
The out-of-the-box SRW App case builds a weather forecast for June 15-16, 2019. Multiple convective weather events during these two days produced over 200 filtered storm reports. Severe weather was clustered in two areas: the Upper Midwest through the Ohio Valley and the Southern Great Plains. This forecast uses a predefined 25-km Continental United States (CONUS) domain (RRFS_CONUS_25km), the Global Forecast System (GFS) version 16 physics suite (FV3_GFS_v16 CCPP), and FV3-based GFS raw external model data for initialization.
Attention
The SRW Application has four levels of support. The steps described in this chapter will work most smoothly on preconfigured (Level 1) systems. This chapter can also serve as a starting point for running the SRW App on other systems (including generic Linux/Mac systems), but the user may need to perform additional troubleshooting.
The overall procedure for generating an experiment is shown in Figure 5.1, with the scripts to generate and run the workflow shown in red. Once the SRW App has been built, as described in Chapter 4, the steps to run a forecast are as follows:
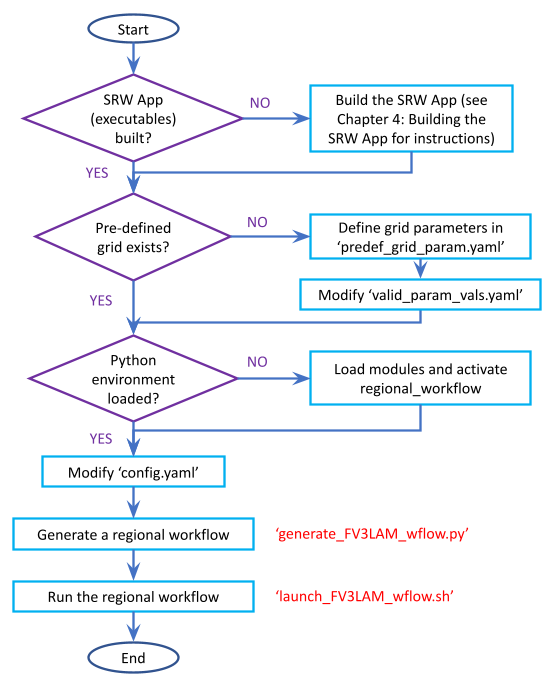
Fig. 5.1 Overall Layout of the SRW App Workflow
5.1. Download and Stage the Data
The SRW App requires input files to run. These include static datasets, initial and boundary conditions files, and model configuration files. On Level 1 systems, the data required to run SRW App tests are already available in the following locations:
Machine |
File location |
|---|---|
Cheyenne |
/glade/p/ral/jntp/UFS_SRW_App/v2p1/input_model_data/ |
Gaea |
/lustre/f2/pdata/ncep/UFS_SRW_App/v2p1/input_model_data/ |
Hera |
/scratch2/BMC/det/UFS_SRW_App/v2p1/input_model_data/ |
Jet |
/mnt/lfs4/BMC/wrfruc/UFS_SRW_App/v2p1/input_model_data/ |
NOAA Cloud |
/contrib/EPIC/UFS_SRW_App/v2p1/input_model_data/ |
Orion |
/work/noaa/fv3-cam/UFS_SRW_App/v2p1/input_model_data/ |
For Level 2-4 systems, the data must be added to the user’s system. Detailed instructions on how to add the data can be found in Section 7.3. Sections 7.1 and 7.2 contain useful background information on the input and output files used in the SRW App.
5.2. Grid Configuration
The SRW App officially supports the four predefined grids shown in Table 5.2. The out-of-the-box SRW App case uses the RRFS_CONUS_25km predefined grid option. More information on the predefined and user-generated grid options can be found in Chapter 8. Users who plan to utilize one of the four predefined domain (grid) options may continue to Step 5.3. Users who plan to create a new custom predefined grid should refer to Section 8.2 for instructions. At a minimum, these users will need to add the new grid name to the valid_param_vals.yaml file and add the corresponding grid-specific parameters in the predef_grid_params.yaml file.
Grid Name |
Grid Type |
Quilting (write component) |
|---|---|---|
RRFS_CONUS_25km |
ESG grid |
lambert_conformal |
RRFS_CONUS_13km |
ESG grid |
lambert_conformal |
RRFS_CONUS_3km |
ESG grid |
lambert_conformal |
SUBCONUS_Ind_3km |
ESG grid |
lambert_conformal |
5.3. Generate the Forecast Experiment
Generating the forecast experiment requires three steps:
The first two steps depend on the platform being used and are described here for each Level 1 platform. Users will need to adjust the instructions to reflect their machine configuration if they are working on a Level 2-4 platform. Information in Chapter 9: Configuring the Workflow can help with this.
5.3.1. Load the Conda Environment for the Regional Workflow
The workflow requires Python3 installed using conda, with the additional packages built in a separate conda evironment named regional_workflow. This environment has the following additional packages: PyYAML, Jinja2, f90nml, scipy, matplotlib, pygrib, cartopy. This conda/Python environment has already been set up on Level 1 platforms and can be activated in the following way:
source <path/to/etc/lmod-setup.sh/OR/lmod-setup.csh> <platform>
module use <path/to/modulefiles>
module load wflow_<platform>
where <platform> refers to a valid machine name (see Section 9.1).
Note
If users source the lmod-setup.sh file on a system that doesn’t need it, it will not cause any problems (it will simply do a module purge).
A brief recipe for building the regional workflow environment on a Linux or Mac system can be found in Section 5.3.2.3.2.
The wflow_<platform> modulefile will then output instructions to activate the regional workflow. The user should run the commands specified in the modulefile output. The command may vary from system to system. For example, if the output says:
Please do the following to activate conda:
> conda activate regional_workflow
then the user should run conda activate regional_workflow. This activates the regional_workflow conda environment, and the user typically sees (regional_workflow) in front of the Terminal prompt at this point.
5.3.1.1. Preparing the Workflow Environment on Non-Level 1 Systems
Users on non-Level 1 systems can copy one of the provided wflow_<platform> files and use it as a template to create a wflow_<platform> file that works for their system. The wflow_macos and wflow_linux template modulefiles are provided in the modulefiles directory. Modifications are required to provide paths for python, miniconda modules, module loads, conda initialization, and the path for user’s regional_workflow conda environment. After making modifications to a wflow_<platform> file, users can run the commands from Step 5.3.1 above to activate the regional workflow.
Note
conda needs to be initialized before running conda activate regional_workflow command. Depending on the user’s system and login setup, this may be accomplished in a variety of ways. Conda initialization usually involves the following command: source <conda_basedir>/etc/profile.d/conda.sh, where <conda_basedir> is the base conda installation directory.
5.3.2. Set Experiment Configuration Parameters
Each experiment requires certain basic information to run (e.g., date, grid, physics suite). This information is specified in config_defaults.yaml and in the user-specified config.yaml file. When generating a new experiment, the SRW App first reads and assigns default values from config_defaults.yaml. Then, it reads and (re)assigns variables from the user’s custom config.yaml file.
For background info on config_defaults.yaml, read Section 5.3.2.1, or jump to Section 5.3.2.2 to continue configuring the experiment.
5.3.2.1. Default configuration: config_defaults.yaml
Note
This section provides background information on available parameters and how the SRW App uses the config_defaults.yaml file. It is informative, but users do not need to modify config_defaults.yaml to run the out-of-the-box case for the SRW App. Therefore, users may skip to Step 5.3.2.2 to continue configuring their experiment.
Configuration parameters in the config_defaults.yaml file appear in Table 5.3. Some of these default values are intentionally invalid in order to ensure that the user assigns valid values in the user-specified config.yaml file. Any settings provided in config.yaml will override the settings in config_defaults.yaml. There is usually no need for a user to modify the default configuration file. Additional information on the default settings can be found in the config_defaults.yaml file comments and in Chapter 9.
Group Name |
Configuration variables |
|---|---|
User |
RUN_ENVIR, MACHINE, MACHINE_FILE, ACCOUNT |
Platform |
WORKFLOW_MANAGER, NCORES_PER_NODE, BUILD_MOD_FN, WFLOW_MOD_FN, BUILD_VER_FN, RUN_VER_FN, SCHED, DOMAIN_PREGEN_BASEDIR, ENV_INIT_SCRIPTS_FPS, PRE_TASK_CMDS, PARTITION_DEFAULT, QUEUE_DEFAULT, PARTITION_HPSS, QUEUE_HPSS, PARTITION_FCST, QUEUE_FCST, RUN_CMD_UTILS, RUN_CMD_FCST, RUN_CMD_POST, SLURM_NATIVE_CMD, MODEL, MET_INSTALL_DIR, METPLUS_PATH, MET_BIN_EXEC, CCPA_OBS_DIR, MRMS_OBS_DIR, NDAS_OBS_DIR |
Workflow |
WORKFLOW_ID, USE_CRON_TO_RELAUNCH, CRON_RELAUNCH_INTVL_MNTS, EXPT_BASEDIR, EXPT_SUBDIR, EXEC_SUBDIR, DOT_OR_USCORE, EXPT_CONFIG_FN, CONSTANTS_FN, RGNL_GRID_NML_FN, FV3_NML_BASE_SUITE_FN, FV3_NML_YAML_CONFIG_FN, FV3_NML_BASE_ENS_FN, FV3_EXEC_FN, DIAG_TABLE_TMPL_FN, FIELD_TABLE_TMPL_FN, DATA_TABLE_TMPL_FN, MODEL_CONFIG_TMPL_FN, NEMS_CONFIG_TMPL_FN, FCST_MODEL, WFLOW_XML_FN, GLOBAL_VAR_DEFNS_FN, EXTRN_MDL_VAR_DEFNS_FN, WFLOW_LAUNCH_SCRIPT_FN, WFLOW_LAUNCH_LOG_FN, CCPP_PHYS_SUITE, GRID_GEN_METHOD, DATE_FIRST_CYCL, DATE_LAST_CYCL, INCR_CYCL_FREQ, FCST_LEN_HRS, GET_OBS, VX_TN, VX_ENSGRID_TN, VX_ENSGRID_PROB_REFC_TN, MAXTRIES_VX_ENSGRID_PROB_REFC, PREEXISTING_DIR_METHOD, VERBOSE, DEBUG, COMPILER |
NCO |
envir, NET, model_ver, RUN, OPSROOT |
Workflow Switches |
RUN_TASK_MAKE_GRID, RUN_TASK_MAKE_OROG, RUN_TASK_MAKE_SFC_CLIMO, RUN_TASK_GET_EXTRN_ICS, RUN_TASK_GET_EXTRN_LBCS, RUN_TASK_MAKE_ICS, RUN_TASK_MAKE_LBCS, RUN_TASK_RUN_FCST, RUN_TASK_RUN_POST, RUN_TASK_GET_OBS_CCPA, RUN_TASK_GET_OBS_MRMS, RUN_TASK_GET_OBS_NDAS, RUN_TASK_VX_GRIDSTAT, RUN_TASK_VX_POINTSTAT, RUN_TASK_VX_ENSGRID, RUN_TASK_VX_ENSPOINT |
task_make_grid |
MAKE_GRID_TN, NNODES_MAKE_GRID, PPN_MAKE_GRID, WTIME_MAKE_GRID, MAXTRIES_MAKE_GRID, GRID_DIR, ESGgrid_LON_CTR, ESGgrid_LAT_CTR, ESGgrid_DELX, ESGgrid_DELY, ESGgrid_NX, ESGgrid_NY, ESGgrid_PAZI, ESGgrid_WIDE_HALO_WIDTH, GFDLgrid_LON_T6_CTR, GFDLgrid_LAT_T6_CTR, GFDLgrid_NUM_CELLS, GFDLgrid_STRETCH_FAC, GFDLgrid_REFINE_RATIO, GFDLgrid_ISTART_OF_RGNL_DOM_ON_T6G, GFDLgrid_IEND_OF_RGNL_DOM_ON_T6G, GFDLgrid_JSTART_OF_RGNL_DOM_ON_T6G, GFDLgrid_JEND_OF_RGNL_DOM_ON_T6G, GFDLgrid_USE_NUM_CELLS_IN_FILENAMES |
task_make_orog |
MAKE_OROG_TN, NNODES_MAKE_OROG, PPN_MAKE_OROG, WTIME_MAKE_OROG, MAXTRIES_MAKE_OROG, KMP_AFFINITY_MAKE_OROG, OMP_NUM_THREADS_MAKE_OROG OMP_STACKSIZE_MAKE_OROG, OROG_DIR |
task_make_sfc_climo |
MAKE_SFC_CLIMO_TN, NNODES_MAKE_SFC_CLIMO, PPN_MAKE_SFC_CLIMO, WTIME_MAKE_SFC_CLIMO, MAXTRIES_MAKE_SFC_CLIMO, KMP_AFFINITY_MAKE_SFC_CLIMO, OMP_NUM_THREADS_MAKE_SFC_CLIMO, OMP_STACKSIZE_MAKE_SFC_CLIMO, SFC_CLIMO_DIR |
task_get_extrn_ics |
GET_EXTRN_ICS_TN, NNODES_GET_EXTRN_ICS, PPN_GET_EXTRN_ICS, WTIME_GET_EXTRN_ICS, MAXTRIES_GET_EXTRN_ICS, EXTRN_MDL_NAME_ICS, EXTRN_MDL_ICS_OFFSET_HRS, FV3GFS_FILE_FMT_ICS, EXTRN_MDL_SYSBASEDIR_ICS, USE_USER_STAGED_EXTRN_FILES, EXTRN_MDL_SOURCE_BASEDIR_ICS, EXTRN_MDL_FILES_ICS, EXTRN_MDL_FILES_ICS, EXTRN_MDL_FILES_ICS, EXTRN_MDL_DATA_STORES, NOMADS, NOMADS_file_type |
task_get_extrn_lbcs |
GET_EXTRN_LBCS_TN, NNODES_GET_EXTRN_LBCS, PPN_GET_EXTRN_LBCS, WTIME_GET_EXTRN_LBCS, MAXTRIES_GET_EXTRN_LBCS, EXTRN_MDL_NAME_LBCS, LBC_SPEC_INTVL_HRS, EXTRN_MDL_LBCS_OFFSET_HRS, FV3GFS_FILE_FMT_LBCS, EXTRN_MDL_SYSBASEDIR_LBCS, USE_USER_STAGED_EXTRN_FILES, EXTRN_MDL_SOURCE_BASEDIR_LBCS, EXTRN_MDL_FILES_LBCS, EXTRN_MDL_DATA_STORE, NOMADS, NOMADS_file_type |
task_make_ics |
MAKE_ICS_TN, NNODES_MAKE_ICS, PPN_MAKE_ICS, WTIME_MAKE_ICS, MAXTRIES_MAKE_ICS, KMP_AFFINITY_MAKE_ICS, OMP_NUM_THREADS_MAKE_ICS, OMP_STACKSIZE_MAKE_ICS, USE_FVCOM, FVCOM_WCSTART, FVCOM_DIR, FVCOM_FILE |
task_make_lbcs |
MAKE_LBCS_TN, NNODES_MAKE_LBCS, PPN_MAKE_LBCS, WTIME_MAKE_LBCS, MAXTRIES_MAKE_LBCS, KMP_AFFINITY_MAKE_LBCS, OMP_NUM_THREADS_MAKE_LBCS, OMP_STACKSIZE_MAKE_LBCS |
task_run_fcst |
RUN_FCST_TN, NNODES_RUN_FCST, PPN_RUN_FCST, WTIME_RUN_FCST, MAXTRIES_RUN_FCST, KMP_AFFINITY_RUN_FCST, OMP_NUM_THREADS_RUN_FCST, OMP_STACKSIZE_RUN_FCST, DT_ATMOS, RESTART_INTERVAL, WRITE_DOPOST, LAYOUT_X, LAYOUT_Y, BLOCKSIZE, QUILTING, PRINT_ESMF, WRTCMP_write_groups, WRTCMP_write_tasks_per_group, WRTCMP_cen_lon, WRTCMP_cen_lat, WRTCMP_lon_lwr_left, WRTCMP_lat_lwr_left, WRTCMP_lon_upr_rght, WRTCMP_lat_upr_rght, WRTCMP_dlon, WRTCMP_dlat, WRTCMP_stdlat1, WRTCMP_stdlat2, WRTCMP_nx, WRTCMP_ny, WRTCMP_dx, WRTCMP_dy, PREDEF_GRID_NAME, USE_MERRA_CLIMO, SFC_CLIMO_FIELDS, FIXgsm, FIXaer, FIXlut, TOPO_DIR, SFC_CLIMO_INPUT_DIR, SYMLINK_FIX_FILES, FNGLAC, FNMXIC, FNTSFC, FNSNOC, FNZORC, FNAISC, FNSMCC, FNMSKH, FIXgsm_FILES_TO_COPY_TO_FIXam, FV3_NML_VARNAME_TO_FIXam_FILES_MAPPING, FV3_NML_VARNAME_TO_SFC_CLIMO_FIELD_MAPPING, CYCLEDIR_LINKS_TO_FIXam_FILES_MAPPING |
task_run_post |
RUN_POST_TN, NNODES_RUN_POST, PPN_RUN_POST, WTIME_RUN_POST, MAXTRIES_RUN_POST, KMP_AFFINITY_RUN_POST, OMP_NUM_THREADS_RUN_POST, OMP_STACKSIZE_RUN_POST, SUB_HOURLY_POST, DT_SUB_HOURLY_POST_MNTS, USE_CUSTOM_POST_CONFIG_FILE, CUSTOM_POST_CONFIG_FP, POST_OUTPUT_DOMAIN_NAME |
Global |
USE_CRTM, CRTM_DIR, DO_ENSEMBLE, NUM_ENS_MEMBERS, NEW_LSCALE, DO_SHUM, ISEED_SHUM, SHUM_MAG, SHUM_LSCALE, SHUM_TSCALE, SHUM_INT, DO_SPPT, ISEED_SPPT, SPPT_MAG, SPPT_LOGIT, SPPT_LSCALE, SPPT_TSCALE, SPPT_INT, SPPT_SFCLIMIT, USE_ZMTNBLCK, DO_SKEB, ISEED_SKEB, SKEB_MAG, SKEB_LSCALE, SKEP_TSCALE, SKEB_INT, SKEBNORM, SKEB_VDOF, DO_SPP, ISEED_SPP, SPP_VAR_LIST, SPP_MAG_LIST, SPP_LSCALE, SPP_TSCALE, SPP_SIGTOP1, SPP_SIGTOP2, SPP_STDDEV_CUTOFF, DO_LSM_SPP, LSM_SPP_TSCALE, LSM_SPP_LSCALE, ISEED_LSM_SPP, LSM_SPP_VAR_LIST, LSM_SPP_MAG_LIST, HALO_BLEND |
task_get_obs_ccpa |
GET_OBS_CCPA_TN, NNODES_GET_OBS_CCPA, PPN_GET_OBS_CCPA, WTIME_GET_OBS_CCPA, MAXTRIES_GET_OBS_CCPA |
task_get_obs_mrms |
GET_OBS_MRMS_TN, NNODES_GET_OBS_MRMS, PPN_GET_OBS_MRMS, WTIME_GET_OBS_MRMS, MAXTRIES_GET_OBS_MRMS |
task_get_obs_ndas |
GET_OBS_NDAS_TN, NNODES_GET_OBS_NDAS, PPN_GET_OBS_NDAS, WTIME_GET_OBS_NDAS, MAXTRIES_GET_OBS_NDAS |
task_run_vx_gridstat |
VX_GRIDSTAT_TN, NNODES_VX_GRIDSTAT, PPN_VX_GRIDSTAT, WTIME_VX_GRIDSTAT, MAXTRIES_VX_GRIDSTAT |
task_run_vx_gridstat_refc |
VX_GRIDSTAT_REFC_TN, NNODES_VX_GRIDSTAT, PPN_VX_GRIDSTAT, WTIME_VX_GRIDSTAT, MAXTRIES_VX_GRIDSTAT_REFC |
task_run_vx_gridstat_retop |
VX_GRIDSTAT_RETOP_TN, NNODES_VX_GRIDSTAT, PPN_VX_GRIDSTAT, WTIME_VX_GRIDSTAT, MAXTRIES_VX_GRIDSTAT_RETOP |
task_run_vx_gridstat_03h |
VX_GRIDSTAT_03h_TN, NNODES_VX_GRIDSTAT, PPN_VX_GRIDSTAT, WTIME_VX_GRIDSTAT, MAXTRIES_VX_GRIDSTAT_03h |
task_run_vx_gridstat_06h |
VX_GRIDSTAT_06h_TN, NNODES_VX_GRIDSTAT, PPN_VX_GRIDSTAT, WTIME_VX_GRIDSTAT, MAXTRIES_VX_GRIDSTAT_06h |
task_run_vx_gridstat_24h |
VX_GRIDSTAT_24h_TN, NNODES_VX_GRIDSTAT, PPN_VX_GRIDSTAT, WTIME_VX_GRIDSTAT, MAXTRIES_VX_GRIDSTAT_24h |
task_run_vx_pointstat |
VX_POINTSTAT_TN, NNODES_VX_POINTSTAT, PPN_VX_POINTSTAT, WTIME_VX_POINTSTAT, MAXTRIES_VX_POINTSTAT |
task_run_vx_ensgrid |
VX_ENSGRID_03h_TN, MAXTRIES_VX_ENSGRID_03h, VX_ENSGRID_06h_TN, MAXTRIES_VX_ENSGRID_06h, VX_ENSGRID_24h_TN, MAXTRIES_VX_ENSGRID_24h, VX_ENSGRID_RETOP_TN, MAXTRIES_VX_ENSGRID_RETOP, VX_ENSGRID_PROB_RETOP_TN, MAXTRIES_VX_ENSGRID_PROB_RETOP, NNODES_VX_ENSGRID, PPN_VX_ENSGRID, WTIME_VX_ENSGRID, MAXTRIES_VX_ENSGRID |
task_run_vx_ensgrid_refc |
VX_ENSGRID_REFC_TN, NNODES_VX_ENSGRID, PPN_VX_ENSGRID, WTIME_VX_ENSGRID, MAXTRIES_VX_ENSGRID_REFC |
task_run_vx_ensgrid_mean |
VX_ENSGRID_MEAN_TN, NNODES_VX_ENSGRID_MEAN, PPN_VX_ENSGRID_MEAN, WTIME_VX_ENSGRID_MEAN, MAXTRIES_VX_ENSGRID_MEAN |
task_run_vx_ensgrid_mean_03h |
VX_ENSGRID_MEAN_03h_TN, NNODES_VX_ENSGRID_MEAN, PPN_VX_ENSGRID_MEAN, WTIME_VX_ENSGRID_MEAN, MAXTRIES_VX_ENSGRID_MEAN_03h |
task_run_vx_ensgrid_mean_06h |
VX_ENSGRID_MEAN_06h_TN, NNODES_VX_ENSGRID_MEAN, PPN_VX_ENSGRID_MEAN, WTIME_VX_ENSGRID_MEAN, MAXTRIES_VX_ENSGRID_MEAN_06h |
task_run_vx_ensgrid_mean_24h |
VX_ENSGRID_MEAN_24h_TN, NNODES_VX_ENSGRID_MEAN, PPN_VX_ENSGRID_MEAN, WTIME_VX_ENSGRID_MEAN, MAXTRIES_VX_ENSGRID_MEAN_24h |
task_run_vx_ensgrid_prob |
VX_ENSGRID_PROB_TN, NNODES_VX_ENSGRID_PROB, PPN_VX_ENSGRID_PROB, WTIME_VX_ENSGRID_PROB, MAXTRIES_VX_ENSGRID_PROB |
task_run_vx_ensgrid_prob_03h |
VX_ENSGRID_PROB_03h_TN, NNODES_VX_ENSGRID_PROB, PPN_VX_ENSGRID_PROB, WTIME_VX_ENSGRID_PROB, MAXTRIES_VX_ENSGRID_PROB_03h |
task_run_vx_ensgrid_prob_06h |
VX_ENSGRID_PROB_06h_TN, NNODES_VX_ENSGRID_PROB, PPN_VX_ENSGRID_PROB, WTIME_VX_ENSGRID_PROB, MAXTRIES_VX_ENSGRID_PROB_06h |
task_run_vx_ensgrid_prob_24h |
VX_ENSGRID_PROB_24h_TN, NNODES_VX_ENSGRID_PROB, PPN_VX_ENSGRID_PROB, WTIME_VX_ENSGRID_PROB, MAXTRIES_VX_ENSGRID_PROB_24h |
task_run_vx_enspoint |
VX_ENSPOINT_TN, NNODES_VX_ENSPOINT, PPN_VX_ENSPOINT, WTIME_VX_ENSPOINT, MAXTRIES_VX_ENSPOINT |
task_run_vx_enspoint_mean |
VX_ENSPOINT_MEAN_TN, NNODES_VX_ENSPOINT_MEAN, PPN_VX_ENSPOINT_MEAN, WTIME_VX_ENSPOINT_MEAN, MAXTRIES_VX_ENSPOINT_MEAN |
task_run_vx_enspoint_prob |
VX_ENSPOINT_PROB_TN, NNODES_VX_ENSPOINT_PROB, PPN_VX_ENSPOINT_PROB, WTIME_VX_ENSPOINT_PROB, MAXTRIES_VX_ENSPOINT_PROB |
5.3.2.2. User-specific configuration: config.yaml
The user must specify certain basic experiment configuration information in a config.yaml file located in the ufs-srweather-app/ush directory. Two example templates are provided in that directory: config.community.yaml and config.nco.yaml. The first file is a minimal example for creating and running an experiment in community mode (with RUN_ENVIR set to community). The second is an example for creating and running an experiment in the NCO (operational) mode (with RUN_ENVIR set to nco). The community mode is recommended in most cases and is fully supported for this release. The operational/NCO mode is typically used by developers at the Environmental Modeling Center (EMC) and at the Global Systems Laboratory (GSL) working on pre-implementation testing for the Rapid Refresh Forecast System (RRFS). Table 5.4 compares the configuration variables that appear in the config.community.yaml with their default values in config_default.yaml.
Parameter |
Default Value |
config.community.yaml Value |
|---|---|---|
RUN_ENVIR |
“nco” |
“community” |
MACHINE |
“BIG_COMPUTER” |
“hera” |
ACCOUNT |
“project_name” |
“an_account” |
MODEL |
“” |
“FV3_GFS_v16_CONUS_25km” |
METPLUS_PATH |
“” |
“” |
MET_INSTALL_DIR |
“” |
“” |
CCPA_OBS_DIR |
“” |
“” |
MRMS_OBS_DIR |
“” |
“” |
NDAS_OBS_DIR |
“” |
“” |
EXPT_SUBDIR |
“” |
“test_community” |
CCPP_PHYS_SUITE |
“FV3_GFS_v16” |
“FV3_GFS_v16” |
DATE_FIRST_CYCL |
“YYYYMMDDHH” |
‘2019061518’ |
DATE_LAST_CYCL |
“YYYYMMDDHH” |
‘2019061518’ |
FCST_LEN_HRS |
24 |
12 |
PREEXISTING_DIR_METHOD |
“delete” |
“rename” |
VERBOSE |
true |
true |
COMPILER |
“intel” |
“intel” |
RUN_TASK_MAKE_GRID |
true |
true |
RUN_TASK_MAKE_OROG |
true |
true |
RUN_TASK_MAKE_SFC_CLIMO |
true |
true |
RUN_TASK_GET_OBS_CCPA |
false |
false |
RUN_TASK_GET_OBS_MRMS |
false |
false |
RUN_TASK_GET_OBS_NDAS |
false |
false |
RUN_TASK_VX_GRIDSTAT |
false |
false |
RUN_TASK_VX_POINTSTAT |
false |
false |
RUN_TASK_VX_ENSGRID |
false |
false |
RUN_TASK_VX_ENSPOINT |
false |
false |
EXTRN_MDL_NAME_ICS |
“FV3GFS” |
“FV3GFS” |
FV3GFS_FILE_FMT_ICS |
“nemsio” |
“grib2” |
EXTRN_MDL_NAME_LBCS |
“FV3GFS” |
“FV3GFS” |
FV3GFS_FILE_FMT_LBCS |
“nemsio” |
“grib2” |
LBC_SPEC_INTVL_HRS |
6 |
6 |
WTIME_RUN_FCST |
“04:30:00” |
“02:00:00” |
QUILTING |
true |
true |
PREDEF_GRID_NAME |
“” |
“RRFS_CONUS_25km” |
DO_ENSEMBLE |
false |
false |
NUM_ENS_MEMBERS |
1 |
2 |
To get started, make a copy of config.community.yaml. From the ufs-srweather-app directory, run:
cd /path/to/ufs-srweather-app/ush
cp config.community.yaml config.yaml
The default settings in this file include a predefined 25-km CONUS grid (RRFS_CONUS_25km), the GFS v16 physics suite (FV3_GFS_v16 CCPP), and FV3-based GFS raw external model data for initialization.
Note
Users who are accustomed to the former shell script workflow can reuse an old config.sh file by setting EXPT_CONFIG_FN: "config.sh" in config_defaults.yaml. Alternatively, users can convert their config.sh file to a config.yaml file by running:
./config_utils.py -c $PWD/config.sh -t $PWD/config_defaults.yaml -o yaml >config.yaml
Next, users should edit the new config.yaml file to customize it for their machine. At a minimum, users must change the MACHINE and ACCOUNT variables. Then, they can choose a name for the experiment directory by setting EXPT_SUBDIR. If users have pre-staged initialization data for the experiment, they can set USE_USER_STAGED_EXTRN_FILES: true, and set the paths to the data for EXTRN_MDL_SOURCE_BASEDIR_ICS and EXTRN_MDL_SOURCE_BASEDIR_LBCS. If the modulefile used to set up the build environment in Section 4.4 uses a GNU compiler, check that the line COMPILER: "gnu" appears in the workflow: section of the config.yaml file. On platforms where Rocoto and cron are available, users can automate resubmission of their experiment workflow by adding the following lines to the workflow: section of the config.yaml file:
USE_CRON_TO_RELAUNCH: true
CRON_RELAUNCH_INTVL_MNTS: 3
Note
Generic Linux and MacOS users should refer to Section 5.3.2.3 for additional details on configuring an experiment and python environment.
Detailed information on additional parameter options can be viewed in Chapter 9: Configuring the Workflow. Additionally, information about the four predefined Limited Area Model (LAM) Grid options can be found in Chapter 8: Limited Area Model (LAM) Grids.
On Level 1 systems, the following fields typically need to be updated or added to the appropriate section of the config.yaml file in order to run the out-of-the-box SRW App case:
user:
MACHINE: hera
ACCOUNT: an_account
workflow:
EXPT_SUBDIR: test_community
task_get_extrn_ics:
USE_USER_STAGED_EXTRN_FILES: true
EXTRN_MDL_SOURCE_BASEDIR_ICS: "/path/to/UFS_SRW_App/v2p1/input_model_data/<model_type>/<data_type>/<YYYYMMDDHH>"
task_get_extrn_lbcs:
USE_USER_STAGED_EXTRN_FILES: true
EXTRN_MDL_SOURCE_BASEDIR_LBCS: "/path/to/UFS_SRW_App/v2p1/input_model_data/<model_type>/<data_type>/<YYYYMMDDHH>"
- where:
MACHINErefers to a valid machine name (see Section 9.1 for options).ACCOUNTrefers to a valid account name. Not all systems require a valid account name, but most do.
Hint
To determine an appropriate ACCOUNT field for Level 1 systems, run
groups, and it will return a list of projects you have permissions for. Not all of the listed projects/groups have an HPC allocation, but those that do are potentially valid account names.EXPT_SUBDIRis changed to an experiment name of the user’s choice.</path/to/>is the path to the SRW App data on the user’s machine (see Section 5.1).<model_type>refers to a subdirectory containing the experiment data from a particular model. Valid values on Level 1 systems correspond to the valid values forEXTRN_MDL_NAME_ICSandEXTRN_MDL_NAME_LBCS(see Chapter 9 for options).<data_type>refers to one of 3 possible data formats:grib2,nemsio, ornetcdf.<YYYYMMDDHH>refers to a subdirectory containing data for the cycle date (in YYYYMMDDHH format).
Note
On JET, users should also add PARTITION_DEFAULT: xjet and PARTITION_FCST: xjet to the platform: section of the config.yaml file.
For example, to run the out-of-the-box experiment on Gaea, add or modify variables in the user, workflow, task_get_extrn_ics, and task_get_extrn_lbcs sections of config.yaml (unmodified variables are not shown in this example):
user: MACHINE: gaea ACCOUNT: hfv3gfs workflow: EXPT_SUBDIR: run_basic_srw task_get_extrn_ics: USE_USER_STAGED_EXTRN_FILES: true EXTRN_MDL_SOURCE_BASEDIR_ICS: /lustre/f2/pdata/ncep/UFS_SRW_App/v2p1/input_model_data/FV3GFS/grib2/2019061518 EXTRN_MDL_DATA_STORES: disk task_get_extrn_lbcs: USE_USER_STAGED_EXTRN_FILES: true EXTRN_MDL_SOURCE_BASEDIR_LBCS: /lustre/f2/pdata/ncep/UFS_SRW_App/v2p1/input_model_data/FV3GFS/grib2/2019061518 EXTRN_MDL_DATA_STORES: disk
To determine whether the config.yaml file adjustments are valid, users can run the following script from the ush directory:
./config_utils.py -c $PWD/config.yaml -v $PWD/config_defaults.yaml
A correct config.yaml file will output a SUCCESS message. A config.yaml file with problems will output a FAILURE message describing the problem. For example:
INVALID ENTRY: EXTRN_MDL_FILES_ICS=[]
FAILURE
Note
The regional workflow must be loaded for the config_utils.py script to validate the config.yaml file.
Valid values for configuration variables should be consistent with those in the ush/valid_param_vals.yaml script. In addition, various sample configuration files can be found within the subdirectories of tests/WE2E/test_configs.
To configure an experiment and python environment for a general Linux or Mac system, see the next section. To configure an experiment to run METplus verification tasks, see Section 5.3.2.4. Otherwise, skip to Section 5.3.3 to generate the workflow.
5.3.2.3. User-Specific Configuration on a General Linux/MacOS System
The configuration process for Linux and MacOS systems is similar to the process for other systems, but it requires a few extra steps.
Note
Examples in this subsection presume that the user is running in the Terminal with a bash shell environment. If this is not the case, users will need to adjust the commands to fit their command line application and shell environment.
5.3.2.3.1. Install/Upgrade Mac-Specific Packages
MacOS requires the installation of a few additional packages and, possibly, an upgrade to bash. Users running on MacOS should execute the following commands:
bash --version
brew install bash # or: brew upgrade bash
brew install coreutils
brew gsed # follow directions to update the PATH env variable
5.3.2.3.2. Creating a conda Environment on Linux and Mac
Users need to create a conda regional_workflow environment. The environment can be stored in a local path, which could be a default location or a user-specified location (e.g. $HOME/condaenv/venvs/ directory). (To determine the default location, use the conda info command, and look for the envs directories list.) A brief recipe for creating a virtual conda environment on non-Level 1 platforms:
conda create --name regional_workflow python=<python3-conda-version>
conda activate regional_workflow
conda install -c conda-forge f90nml
conda install jinja2
conda install pyyaml
# install packages for graphics environment
conda install scipy
conda install matplotlib
conda install -c conda-forge pygrib
conda install cartopy
# verify the packages installed
conda list
conda deactivate
where <python3-conda-version> is a numeric version (e.g. 3.9.12) in the conda base installation resulting from the query python3 --version.
5.3.2.3.3. Configuring an Experiment on General Linux and MacOS Systems
Optional: Install Rocoto
Note
Users may install Rocoto if they want to make use of a workflow manager to run their experiments. However, this option has not yet been tested on MacOS and has had limited testing on general Linux plaforms.
Configure the SRW App:
Configure an experiment using a template. Copy the contents of config.community.yaml into config.yaml:
cd /path/to/ufs-srweather-app/ush
cp config.community.yaml config.yaml
In the config.yaml file, set MACHINE: macos or MACHINE: linux, and modify the account and experiment info. For example:
user:
RUN_ENVIR: community
MACHINE: macos
ACCOUNT: user
workflow:
EXPT_SUBDIR: test_community
PREEXISTING_DIR_METHOD: rename
VERBOSE: true
COMPILER: gnu
task_get_extrn_ics:
USE_USER_STAGED_EXTRN_FILES: true
EXTRN_MDL_SOURCE_BASEDIR_ICS: /path/to/input_model_data/FV3GFS/grib2/2019061518
EXTRN_MDL_DATA_STORES: disk
task_get_extrn_lbcs:
USE_USER_STAGED_EXTRN_FILES: true
EXTRN_MDL_SOURCE_BASEDIR_LBCS: /path/to/input_model_data/FV3GFS/grib2/2019061518
EXTRN_MDL_DATA_STORES: disk
task_run_fcst:
PREDEF_GRID_NAME: RRFS_CONUS_25km
QUILTING: true
Due to the limited number of processors on MacOS systems, users must also configure the domain decomposition parameters directly in the section of the predef_grid_params.yaml file pertaining to the grid they want to use. Domain decomposition needs to take into account the number of available CPUs and configure the variables LAYOUT_X, LAYOUT_Y, and WRTCMP_write_tasks_per_group accordingly.
The example below is for systems with 8 CPUs:
task_run_fcst:
LAYOUT_X: 3
LAYOUT_Y: 2
WRTCMP_write_tasks_per_group: 2
Note
The number of MPI processes required by the forecast will be equal to LAYOUT_X * LAYOUT_Y + WRTCMP_write_tasks_per_group.
For a machine with 4 CPUs, the following domain decomposition could be used:
task_run_fcst:
LAYOUT_X: 3
LAYOUT_Y: 1
WRTCMP_write_tasks_per_group: 1
Configure the Machine File
Configure a macos.yaml or linux.yaml machine file in ufs-srweather-app/ush/machine based on the number of CPUs (NCORES_PER_NODE) in the system (usually 8 or 4 in MacOS; varies on Linux systems). Job scheduler (SCHED) options can be viewed here. Users must also set the path to the fix file directories.
platform:
# Architecture information
WORKFLOW_MANAGER: none
NCORES_PER_NODE: 8
SCHED: none
# Run commands for executables
RUN_CMD_FCST: 'mpirun -np ${PE_MEMBER01}'
RUN_CMD_POST: 'mpirun -np 4'
RUN_CMD_SERIAL: time
RUN_CMD_UTILS: 'mpirun -np 4'
# Commands to run at the start of each workflow task.
PRE_TASK_CMDS: '{ ulimit -a; }'
task_make_orog:
TOPO_DIR: path/to/FIXgsm/files # (path to location of static input files used by the make_orog task)
task_make_sfc_climo:
SFC_CLIMO_INPUT_DIR: path/to/FIXgsm/files # (path to location of static surface climatology input fields used by sfc_climo_gen)
task_run_fcst:
FIXaer: /path/to/FIXaer/files
FIXgsm: /path/to/FIXgsm/files
FIXlut: /path/to/FIXlut/files
data:
FV3GFS: /Users/username/DATA/UFS/FV3GFS # (used by setup.py to set the values of EXTRN_MDL_SOURCE_BASEDIR_ICS and EXTRN_MDL_SOURCE_BASEDIR_LBCS)
The data: section of the machine file can point to various data sources that the user has pre-staged on disk. For example:
data:
FV3GFS:
nemsio: /Users/username/DATA/UFS/FV3GFS/nemsio
grib2: /Users/username/DATA/UFS/FV3GFS/grib2
netcdf: /Users/username/DATA/UFS/FV3GFS/netcdf
RAP: /Users/username/DATA/UFS/RAP/grib2
HRRR: /Users/username/DATA/UFS/HRRR/grib2
This can be helpful when conducting multiple experiments with different types of data.
5.3.2.4. Configure METplus Verification Suite (Optional)
Users who want to use the METplus verification suite to evaluate their forecasts need to add additional information to their config.yaml file. Other users may skip to the next section.
Attention
METplus installation is not included as part of the build process for this release of the SRW App. However, METplus is preinstalled on many Level 1 & 2 systems. For the v2.1.0 release, METplus use is supported on systems with a functioning METplus installation, although installation itself is not supported. For more information about METplus, see Section 6.4.
Note
If METplus users update their METplus installation, they must update the module load statements in ufs-srweather-app/modulefiles/tasks/<machine>/run_vx.local file to correspond to their system’s updated installation:
module use -a </path/to/met/modulefiles/>
module load met/<version.X.X>
To use METplus verification, the path to the MET and METplus directories must be added to config.yaml:
platform:
METPLUS_PATH: </path/to/METplus/METplus-4.1.0>
MET_INSTALL_DIR: </path/to/met/10.1.0>
Users who have already staged the observation data needed for METplus (i.e., the CCPA, MRMS, and NDAS data) on their system should set the path to this data and set the corresponding RUN_TASK_GET_OBS_* parameters to false in config.yaml.
platform:
CCPA_OBS_DIR: /path/to/UFS_SRW_App/v2p1/obs_data/ccpa/proc
MRMS_OBS_DIR: /path/to/UFS_SRW_App/v2p1/obs_data/mrms/proc
NDAS_OBS_DIR: /path/to/UFS_SRW_App/v2p1/obs_data/ndas/proc
workflow_switches:
RUN_TASK_GET_OBS_CCPA: false
RUN_TASK_GET_OBS_MRMS: false
RUN_TASK_GET_OBS_NDAS: false
If users have access to NOAA HPSS but have not pre-staged the data, they can simply set the RUN_TASK_GET_OBS_* tasks to true, and the machine will attempt to download the appropriate data from NOAA HPSS. In this case, the *_OBS_DIR paths must be set to the location where users want the downloaded data to reside.
Users who do not have access to NOAA HPSS and do not have the data on their system will need to download CCPA, MRMS, and NDAS data manually from collections of publicly available data, such as the ones listed here.
Next, the verification tasks must be turned on according to the user’s needs. Users should add some or all of the following tasks to config.yaml, depending on the verification procedure(s) they have in mind:
workflow_switches:
RUN_TASK_VX_GRIDSTAT: true
RUN_TASK_VX_POINTSTAT: true
RUN_TASK_VX_ENSGRID: true
RUN_TASK_VX_ENSPOINT: true
These tasks are independent, so users may set some values to true and others to false depending on the needs of their experiment. Note that the ENSGRID and ENSPOINT tasks apply only to ensemble model verification. Additional verification tasks appear in Table 5.6. More details on all of the parameters in this section are available in Section 9.5.2.
5.3.3. Generate the Regional Workflow
Run the following command from the ufs-srweather-app/ush directory to generate the workflow:
./generate_FV3LAM_wflow.py
The last line of output from this script, starting with */1 * * * * or */3 * * * *, can be saved and used later to automatically run portions of the workflow if users have the Rocoto workflow manager installed on their system.
This workflow generation script creates an experiment directory and populates it with all the data needed to run through the workflow. The flowchart in Figure 5.2 describes the experiment generation process. First, generate_FV3LAM_wflow.py runs the setup.py script to set the configuration parameters. Second, it symlinks the time-independent (fix) files and other necessary data input files from their location to the experiment directory ($EXPTDIR). Third, it creates the input namelist file input.nml based on the input.nml.FV3 file in the parm directory. Lastly, it creates the workflow XML file FV3LAM_wflow.xml that is executed when running the experiment with the Rocoto workflow manager.
The setup.py script reads three other configuration scripts in order: (1) config_defaults.yaml (Section 5.3.2.1), (2) config.yaml (Section 5.3.2.2), and (3) set_predef_grid_params.py. If a parameter is specified differently in these scripts, the file containing the last defined value will be used.
The generated workflow will appear in $EXPTDIR, where EXPTDIR=${EXPT_BASEDIR}/${EXPT_SUBDIR}. These variables were specified in config_defaults.yaml and config.yaml in Step 5.3.2. The settings for these paths can also be viewed in the console output from the ./generate_FV3LAM_wflow.py script or in the log.generate_FV3LAM_wflow file, which can be found in $EXPTDIR.
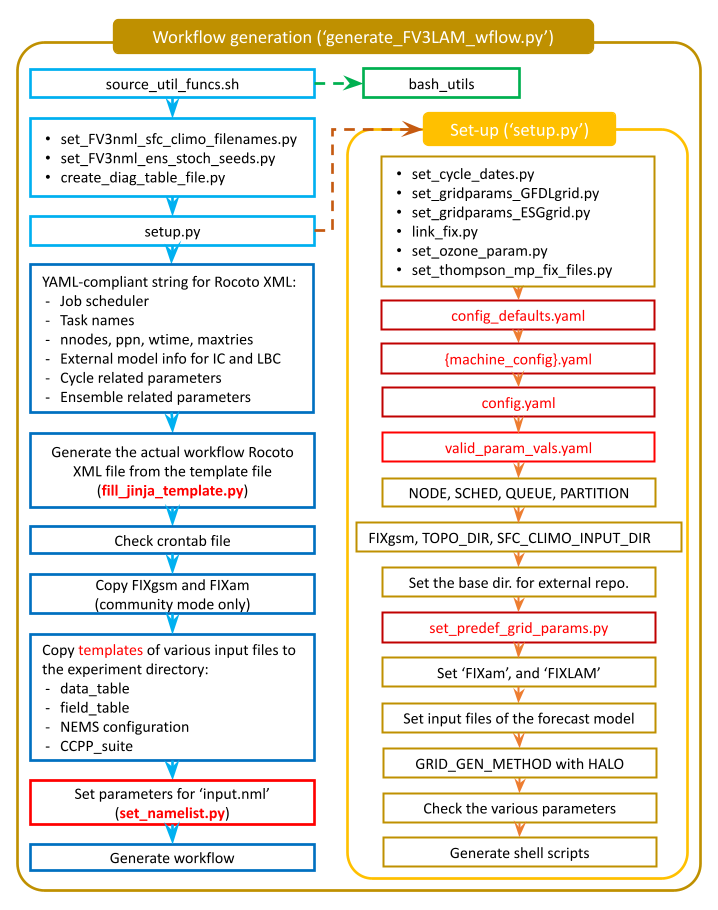
Fig. 5.2 Experiment Generation Description
5.3.4. Description of Workflow Tasks
Note
This section gives a general overview of workflow tasks. To begin running the workflow, skip to Step 5.4
Figure 5.3 illustrates the overall workflow. Individual tasks that make up the workflow are specified in the FV3LAM_wflow.xml file. Table 5.5 describes the function of each baseline task. The first three pre-processing tasks; MAKE_GRID, MAKE_OROG, and MAKE_SFC_CLIMO; are optional. If the user stages pre-generated grid, orography, and surface climatology fix files, these three tasks can be skipped by adding the following lines to the config.yaml file before running the generate_FV3LAM_wflow.py script:
workflow_switches:
RUN_TASK_MAKE_GRID: false
RUN_TASK_MAKE_OROG: false
RUN_TASK_MAKE_SFC_CLIMO: false
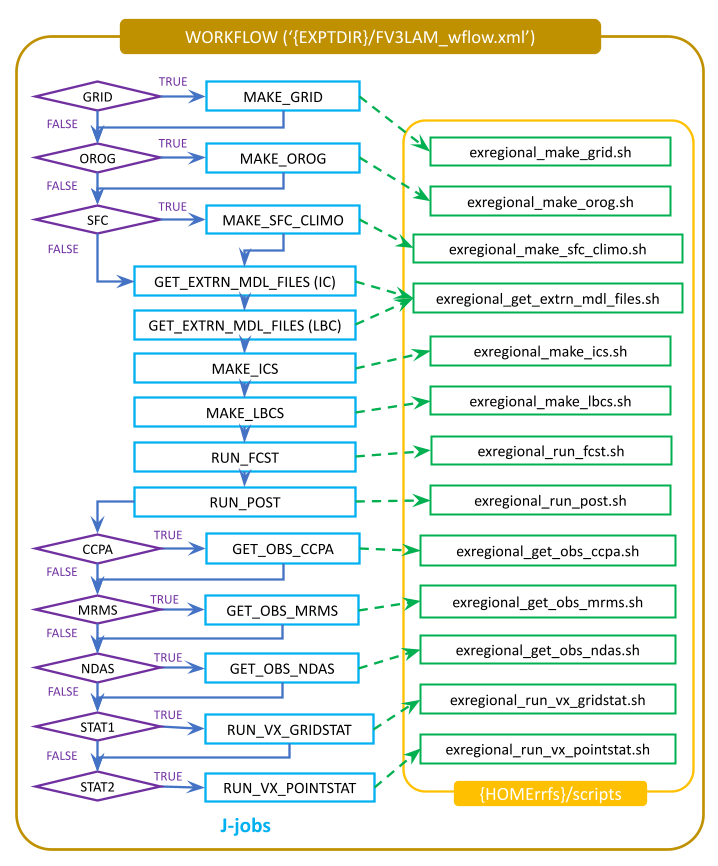
Fig. 5.3 Flowchart of the Workflow Tasks
The FV3LAM_wflow.xml file runs the specific j-job scripts (jobs/JREGIONAL_[task name]) in the prescribed order when the experiment is launched via the launch_FV3LAM_wflow.sh script or the rocotorun command. Each j-job task has its own source script (or “ex-script”) named exregional_[task name].sh in the scripts directory. Two database files named FV3LAM_wflow.db and FV3LAM_wflow_lock.db are generated and updated by the Rocoto calls. There is usually no need for users to modify these files. To relaunch the workflow from scratch, delete these two *.db files and then call the launch script repeatedly for each task.
Workflow Task |
Task Description |
|---|---|
make_grid |
Pre-processing task to generate regional grid files. Only needs to be run once per experiment. |
make_orog |
Pre-processing task to generate orography files. Only needs to be run once per experiment. |
make_sfc_climo |
Pre-processing task to generate surface climatology files. Only needs to be run once per experiment. |
get_extrn_ics |
Cycle-specific task to obtain external data for the initial conditions (ICs) |
get_extrn_lbcs |
Cycle-specific task to obtain external data for the lateral boundary conditions (LBCs) |
make_ics |
Generate initial conditions from the external data |
make_lbcs |
Generate LBCs from the external data |
run_fcst |
Run the forecast model (UFS Weather Model) |
run_post |
Run the post-processing tool (UPP) |
In addition to the baseline tasks described in Table 5.5 above, users may choose to run some or all of the METplus verification tasks. These tasks are described in Table 5.6 below.
Workflow Task |
Task Description |
|---|---|
GET_OBS_CCPA |
Retrieves and organizes hourly CCPA data from NOAA
HPSS. Can only be run if |
GET_OBS_NDAS |
Retrieves and organizes hourly NDAS data from NOAA
HPSS. Can only be run if |
GET_OBS_MRMS |
Retrieves and organizes hourly MRMS composite
reflectivity and echo top data from NOAA HPSS. Can
only be run if |
VX_GRIDSTAT |
Runs METplus grid-to-grid verification for 1-h accumulated precipitation |
VX_GRIDSTAT_REFC |
Runs METplus grid-to-grid verification for composite reflectivity |
VX_GRIDSTAT_RETOP |
Runs METplus grid-to-grid verification for echo top |
VX_GRIDSTAT_##h |
Runs METplus grid-to-grid verification for 3-h, 6-h, and
24-h (i.e., daily) accumulated precipitation. Valid values
for |
VX_POINTSTAT |
Runs METplus grid-to-point verification for surface and upper-air variables |
VX_ENSGRID |
Runs METplus grid-to-grid ensemble verification for 1-h
accumulated precipitation. Can only be run if
|
VX_ENSGRID_REFC |
Runs METplus grid-to-grid ensemble verification for
composite reflectivity. Can only be run if
|
VX_ENSGRID_RETOP |
Runs METplus grid-to-grid ensemble verification for
echo top. Can only be run if |
VX_ENSGRID_##h |
Runs METplus grid-to-grid ensemble verification for 3-h,
6-h, and 24-h (i.e., daily) accumulated precipitation.
Valid values for |
VX_ENSGRID_MEAN |
Runs METplus grid-to-grid verification for ensemble mean
1-h accumulated precipitation. Can only be run if
|
VX_ENSGRID_PROB |
Runs METplus grid-to-grid verification for 1-h accumulated
precipitation probabilistic output. Can only be run if
|
VX_ENSGRID_MEAN_##h |
Runs METplus grid-to-grid verification for ensemble mean
3-h, 6-h, and 24h (i.e., daily) accumulated precipitation.
Valid values for |
VX_ENSGRID_PROB_##h |
Runs METplus grid-to-grid verification for 3-h, 6-h, and
24h (i.e., daily) accumulated precipitation probabilistic
output. Valid values for |
VX_ENSGRID_PROB_REFC |
Runs METplus grid-to-grid verification for ensemble
probabilities for composite reflectivity. Can only be run
if |
VX_ENSGRID_PROB_RETOP |
Runs METplus grid-to-grid verification for ensemble
probabilities for echo top. Can only be run if
|
VX_ENSPOINT |
Runs METplus grid-to-point ensemble verification for
surface and upper-air variables. Can only be run if
|
VX_ENSPOINT_MEAN |
Runs METplus grid-to-point verification for ensemble mean
surface and upper-air variables. Can only be run if
|
VX_ENSPOINT_PROB |
Runs METplus grid-to-point verification for ensemble
probabilities for surface and upper-air variables. Can
only be run if |
5.4. Run the Workflow
The workflow can be run using the Rocoto workflow manager (see Section 5.4.1) or using standalone wrapper scripts (see Section 5.4.2).
Attention
If users are running the SRW App on a system that does not have Rocoto installed (e.g., Level 3 & 4 systems, such as MacOS or generic Linux systems), they should follow the process outlined in Section 5.4.2 instead of the instructions in this section.
5.4.1. Run the Workflow Using Rocoto
The information in this section assumes that Rocoto is available on the desired platform. All official HPC platforms for the UFS SRW App release make use of the Rocoto workflow management software for running experiments. However, if Rocoto is not available, it is still possible to run the workflow using stand-alone scripts according to the process outlined in Section 5.4.2.
There are three ways to run the workflow with Rocoto: (1) automation via crontab (2) by calling the launch_FV3LAM_wflow.sh script, and (3) by manually issuing the rocotorun command.
Note
Users may find it helpful to review Chapter 10 to gain a better understanding of Rocoto commands and workflow management before continuing, but this is not required to run the experiment.
Optionally, an environment variable can be set to navigate to the $EXPTDIR more easily. If the login shell is bash, it can be set as follows:
export EXPTDIR=/<path-to-experiment>/<directory_name>
If the login shell is csh/tcsh, it can be set using:
setenv EXPTDIR /<path-to-experiment>/<directory_name>
5.4.1.1. Automated Option
The simplest way to run the Rocoto workflow is to automate the process using a job scheduler such as Cron. For automatic resubmission of the workflow at regular intervals (e.g., every 2 minutes), the user can add the following commands to their config.yaml file before generating the experiment:
USE_CRON_TO_RELAUNCH: true
CRON_RELAUNCH_INTVL_MNTS: 3
This will automatically add an appropriate entry to the user’s cron table and launch the workflow. Alternatively, the user can add a crontab entry manually using the crontab -e command. As mentioned in Section 5.3.3, the last line of output from ./generate_FV3LAM_wflow.py (starting with */3 * * * *), can be pasted into the crontab file. It can also be found in the $EXPTDIR/log.generate_FV3LAM_wflow file. The crontab entry should resemble the following:
*/3 * * * * cd <path/to/experiment/subdirectory> && ./launch_FV3LAM_wflow.sh called_from_cron="TRUE"
where <path/to/experiment/subdirectory> is changed to correspond to the user’s $EXPTDIR. The number 3 can be changed to a different positive integer and simply means that the workflow will be resubmitted every three minutes.
Hint
On NOAA Cloud instances,
*/1 * * * *(orCRON_RELAUNCH_INTVL_MNTS: 1) is the preferred option for cron jobs because compute nodes will shut down if they remain idle too long. If the compute node shuts down, it can take 15-20 minutes to start up a new one.On other NOAA HPC systems, admins discourage the
*/1 * * * *due to load problems.*/3 * * * *(orCRON_RELAUNCH_INTVL_MNTS: 3) is the preferred option for cron jobs on non-NOAA Cloud systems.
To check the experiment progress:
cd $EXPTDIR
rocotostat -w FV3LAM_wflow.xml -d FV3LAM_wflow.db -v 10
After finishing the experiment, open the crontab using crontab -e and delete the crontab entry.
Note
On Orion, cron is only available on the orion-login-1 node, so users will need to work on that node when running cron jobs on Orion.
The workflow run is complete when all tasks have “SUCCEEDED”. If everything goes smoothly, users will eventually see a workflow status table similar to the following:
CYCLE TASK JOBID STATE EXIT STATUS TRIES DURATION
==========================================================================================================
201906151800 make_grid 4953154 SUCCEEDED 0 1 5.0
201906151800 make_orog 4953176 SUCCEEDED 0 1 26.0
201906151800 make_sfc_climo 4953179 SUCCEEDED 0 1 33.0
201906151800 get_extrn_ics 4953155 SUCCEEDED 0 1 2.0
201906151800 get_extrn_lbcs 4953156 SUCCEEDED 0 1 2.0
201906151800 make_ics 4953184 SUCCEEDED 0 1 16.0
201906151800 make_lbcs 4953185 SUCCEEDED 0 1 71.0
201906151800 run_fcst 4953196 SUCCEEDED 0 1 1035.0
201906151800 run_post_f000 4953244 SUCCEEDED 0 1 5.0
201906151800 run_post_f001 4953245 SUCCEEDED 0 1 4.0
...
201906151800 run_post_f012 4953381 SUCCEEDED 0 1 7.0
If users choose to run METplus verification tasks as part of their experiment, the output above will include additional lines after run_post_f012. The output will resemble the following but may be significantly longer when using ensemble verification:
CYCLE TASK JOBID STATE EXIT STATUS TRIES DURATION
==========================================================================================================
201906151800 make_grid 30466134 SUCCEEDED 0 1 5.0
...
201906151800 run_post_f012 30468271 SUCCEEDED 0 1 7.0
201906151800 run_gridstatvx 30468420 SUCCEEDED 0 1 53.0
201906151800 run_gridstatvx_refc 30468421 SUCCEEDED 0 1 934.0
201906151800 run_gridstatvx_retop 30468422 SUCCEEDED 0 1 1002.0
201906151800 run_gridstatvx_03h 30468491 SUCCEEDED 0 1 43.0
201906151800 run_gridstatvx_06h 30468492 SUCCEEDED 0 1 29.0
201906151800 run_gridstatvx_24h 30468493 SUCCEEDED 0 1 20.0
201906151800 run_pointstatvx 30468423 SUCCEEDED 0 1 670.0
5.4.1.2. Launch the Rocoto Workflow Using a Script
Users who prefer not to automate their experiments can run the Rocoto workflow using the launch_FV3LAM_wflow.sh script provided. Simply call it without any arguments from the experiment directory:
cd $EXPTDIR
./launch_FV3LAM_wflow.sh
This script creates a log file named log.launch_FV3LAM_wflow in $EXPTDIR or appends information to the file if it already exists. The launch script also creates the log/FV3LAM_wflow.log file, which shows Rocoto task information. Check the end of the log file periodically to see how the experiment is progressing:
tail -n 40 log.launch_FV3LAM_wflow
In order to launch additional tasks in the workflow, call the launch script again; this action will need to be repeated until all tasks in the workflow have been launched. To (re)launch the workflow and check its progress on a single line, run:
./launch_FV3LAM_wflow.sh; tail -n 40 log.launch_FV3LAM_wflow
This will output the last 40 lines of the log file, which list the status of the workflow tasks (e.g., SUCCEEDED, DEAD, RUNNING, SUBMITTING, QUEUED). The number 40 can be changed according to the user’s preferences. The output will look similar to this:
CYCLE TASK JOBID STATE EXIT STATUS TRIES DURATION
======================================================================================================
202006170000 make_grid druby://hfe01:33728 SUBMITTING - 0 0.0
202006170000 make_orog - - - - -
202006170000 make_sfc_climo - - - - -
202006170000 get_extrn_ics druby://hfe01:33728 SUBMITTING - 0 0.0
202006170000 get_extrn_lbcs druby://hfe01:33728 SUBMITTING - 0 0.0
202006170000 make_ics - - - - -
202006170000 make_lbcs - - - - -
202006170000 run_fcst - - - - -
202006170000 run_post_00 - - - - -
202006170000 run_post_01 - - - - -
202006170000 run_post_02 - - - - -
202006170000 run_post_03 - - - - -
202006170000 run_post_04 - - - - -
202006170000 run_post_05 - - - - -
202006170000 run_post_06 - - - - -
Summary of workflow status:
~~~~~~~~~~~~~~~~~~~~~~~~~~
0 out of 1 cycles completed.
Workflow status: IN PROGRESS
If all the tasks complete successfully, the “Workflow status” at the bottom of the log file will change from “IN PROGRESS” to “SUCCESS”. If certain tasks could not complete, the “Workflow status” will instead change to “FAILURE”. Error messages for each task can be found in the task log files located in $EXPTDIR/log.
The workflow run is complete when all tasks have “SUCCEEDED”, and the rocotostat command outputs a table similar to the one above.
5.4.1.3. Launch the Rocoto Workflow Manually
Load Rocoto
Instead of running the ./launch_FV3LAM_wflow.sh script, users can load Rocoto and any other required modules manually. This gives the user more control over the process and allows them to view experiment progress more easily. On Level 1 systems, the Rocoto modules are loaded automatically in Step 5.3.1. For most other systems, users can load a modified wflow_<platform> modulefile, or they can use a variant on the following commands to load the Rocoto module:
module use <path_to_rocoto_package>
module load rocoto
Some systems may require a version number (e.g., module load rocoto/1.3.3)
Run the Rocoto Workflow
After loading Rocoto, cd to the experiment directory and call rocotorun to launch the workflow tasks. This will start any tasks that do not have a dependency. As the workflow progresses through its stages, rocotostat will show the state of each task and allow users to monitor progress:
cd $EXPTDIR
rocotorun -w FV3LAM_wflow.xml -d FV3LAM_wflow.db -v 10
rocotostat -w FV3LAM_wflow.xml -d FV3LAM_wflow.db -v 10
The rocotorun and rocotostat commands above will need to be resubmitted regularly and repeatedly until the experiment is finished. In part, this is to avoid having the system time out. This also ensures that when one task ends, tasks dependent on it will run as soon as possible, and rocotostat will capture the new progress.
If the experiment fails, the rocotostat command will indicate which task failed. Users can look at the log file in the log subdirectory for the failed task to determine what caused the failure. For example, if the make_grid task failed, users can open the make_grid.log file to see what caused the problem:
cd $EXPTDIR/log
vi make_grid.log
Note
If users have the Slurm workload manager on their system, they can run the squeue command in lieu of rocotostat to check what jobs are currently running.
5.4.2. Run the Workflow Using Stand-Alone Scripts
The regional workflow can be run using standalone shell scripts in cases where the Rocoto software is not available on a given platform. If Rocoto is available, see Section 5.4.1 to run the workflow using Rocoto.
Attention
When working on an HPC system, users should allocate a compute node prior to running their experiment. The proper command will depend on the system’s resource manager, but some guidance is offered in Section 3.1.4. It may be necessay to reload the regional workflow (see Section 5.3.1). It may also be necessary to load the build_<platform>_<compiler> scripts as described in Section 4.4.2.
cdinto the experiment directory that has been created after generating the regional workflow (Section 5.3.3). For example, fromush, presuming default directory settings:cd ../../expt_dirs/test_communitySet the environment variable
$EXPTDIRfor either bash or csh, respectively:export EXPTDIR=`pwd` setenv EXPTDIR `pwd`
Set the
PDYandcycenvironment variables.PDYrefers to the first 8 characters (YYYYMMDD) of theDATE_FIRST_CYCLvariable defined in theconfig.yaml.cycrefers to the last two digits ofDATE_FIRST_CYCL(HH) defined inconfig.yaml. For example, if theconfig.yamlfile definesDATE_FIRST_CYCL: '2019061518', the user should run:export PDY=20190615 && export cyc=18before running the wrapper scripts.
Copy the wrapper scripts from the
ushdirectory into the experiment directory. Each workflow task has a wrapper script that sets environment variables and runs the job script. IfSRW=<path/to>/ufs-srweather-app, thencp $SRW/ush/wrappers/* .Substitute shell-script headers in all run_*.sh scripts as following using
gsedon MacOS orsedon Linux:gsed -i -e "s|\/bin\/sh|\/usr\/bin\/env bash|" run_*.sh # MacOSsed -i -e "s|\/bin\/sh|\/usr\/bin\/env bash|" run_*.sh # LinuxNote that if you attempt to copy-paste the above commands, the double quotes in the
sedorgsedcommands may not be copied properly to your terminal window. It is safer to retype the double-quotes in a terminal. Alternatively, you could use the text editor to replace the shell-script headers (the first line) to#!/usr/bin/env bash.Substitutions of Bash script headers are also needed for scripts in directories
$SRW/jobsand$SRW/scripts. Similarly to the previous step, the substitution could use streamline editorgsedon MacOS,sedon Linux, or any text editor.gsed -i -e "s|\/bin\/bash|\/usr\/bin\/env bash|" $SRW/jobs/JREGIONAL_* # MacOS gsed -i -e "s|\/bin\/bash|\/usr\/bin\/env bash|" $SRW/scripts/exregional* # MacOS
sed -i -e "s|\/bin\/bash|\/usr\/bin\/env bash|" $SRW/jobs/JREGIONAL_* # Linux sed -i -e "s|\/bin\/bash|\/usr\/bin\/env bash|" $SRW/scripts/exregional* # Linux
Set ulimit to soft resource limits, using either
sedorgsedas in previous steps:ulimit -S -s unlimited gsed -i -e "s|ulimit \-s|ulimit \-S \-s|" $SRW/scripts/exregional* # MacOS sed -i -e "s|ulimit \-s|ulimit \-S \-s|" $SRW/scripts/exregional* # Linux
Set the
OMP_NUM_THREADSvariable.export OMP_NUM_THREADS=1Run each of the listed scripts in order. Scripts with the same stage number (listed in Table 5.7) may be run simultaneously.
./run_make_grid.sh ./run_get_ics.sh ./run_get_lbcs.sh ./run_make_orog.sh ./run_make_sfc_climo.sh ./run_make_ics.sh ./run_make_lbcs.sh ./run_fcst.sh ./run_post.sh
Each task should finish with error code 0. For example:
End exregional_get_extrn_mdl_files.sh at Wed Nov 16 18:08:19 UTC 2022 with error code 0 (time elapsed: 00:00:01)
Check the batch script output file in your experiment directory for a “SUCCESS” message near the end of the file.
Stage/ |
Task Run Script |
Number of Processors |
Wall Clock Time (H:mm) |
|---|---|---|---|
1 |
run_get_ics.sh |
1 |
0:20 (depends on HPSS vs FTP vs staged-on-disk) |
1 |
run_get_lbcs.sh |
1 |
0:20 (depends on HPSS vs FTP vs staged-on-disk) |
1 |
run_make_grid.sh |
24 |
0:20 |
2 |
run_make_orog.sh |
24 |
0:20 |
3 |
run_make_sfc_climo.sh |
48 |
0:20 |
4 |
run_make_ics.sh |
48 |
0:30 |
4 |
run_make_lbcs.sh |
48 |
0:30 |
5 |
run_fcst.sh |
48 |
0:30 |
6 |
run_post.sh |
48 |
0:25 (2 min per output forecast hour) |
Users can access log files for specific tasks in the $EXPTDIR/log directory. To see how the experiment is progressing, users can also check the end of the log.launch_FV3LAM_wflow file from the command line:
tail -n 40 log.launch_FV3LAM_wflow
Hint
If any of the scripts return an error that “Primary job terminated normally, but one process returned a non-zero exit code,” there may not be enough space on one node to run the process. On an HPC system, the user will need to allocate a(nother) compute node. The process for doing so is system-dependent, and users should check the documentation available for their HPC system. Instructions for allocating a compute node on NOAA HPC systems can be viewed in Section 3.1.4 as an example.
Note
On most HPC systems, users will need to submit a batch job to run multi-processor jobs. On some HPC systems, users may be able to run the first jobs (serial) on a login node/command-line. Example scripts for Slurm (Hera) and PBS (Cheyenne) resource managers are provided (sq_job.sh and qsub_job.sh, respectively). These examples will need to be adapted to each user’s system. Alternatively, some batch systems allow users to specify most of the settings on the command line (with the sbatch or qsub command, for example).
5.5. Plot the Output
Two python scripts are provided to generate plots from the FV3-LAM post-processed GRIB2 output. Information on how to generate the graphics can be found in Chapter 12.